Abstract
Contemporary visuo-motor dexterity models often rely on expressive policy classes with diffusion and transformer backbones to achieve strong performance. However, these architectures require significant data and computational resources, and remain far from reliable, particularly for multi-fingered dexterity. Importantly, they model skills as reactive mappings and rely on fixed-horizon action chunking, creating a rigid trade-off between temporal coherence and reactivity. To address these issues, we first introduce Unified Behavioral Models (UBMs), a framework to represent dexterous skills as coupled dynamical systems that capture how visual features of the environment (visual flow) and proprioceptive states of the robot (action flow) co-evolve. As such, UBMs ensure temporal coherence by construction rather than heuristic averaging. Unlike world models that attempt to predict the impact of arbitrary robot actions on the environment, UBMs target behavioral dynamics that encode how demonstrated robot behavior is related to desired impacts on the environment. A UBM can be viewed as a pseudo planner: given an initial condition, it computes the desired robot behavior over the entire skill horizon, while simultaneously “imagining” the resulting flow of visual features. To operationalize UBMs, we propose Koopman-UBM, a first instantiation of UBMs as a structured latent linear system. K-UBM is computationally efficient, enabling reactivity and adaptation via an online replanning strategy: the model acts as its own runtime monitor, automatically triggering replanning when predicted and observed visual flow diverge beyond a threshold. Across seven simulated tasks and four real-world tasks, our approach matches or exceeds the performance of state-of-the-art baselines, while offering considerably faster inference, smooth execution, robustness to occlusions, and flexible replanning.
Introduction to K-UBM
Method
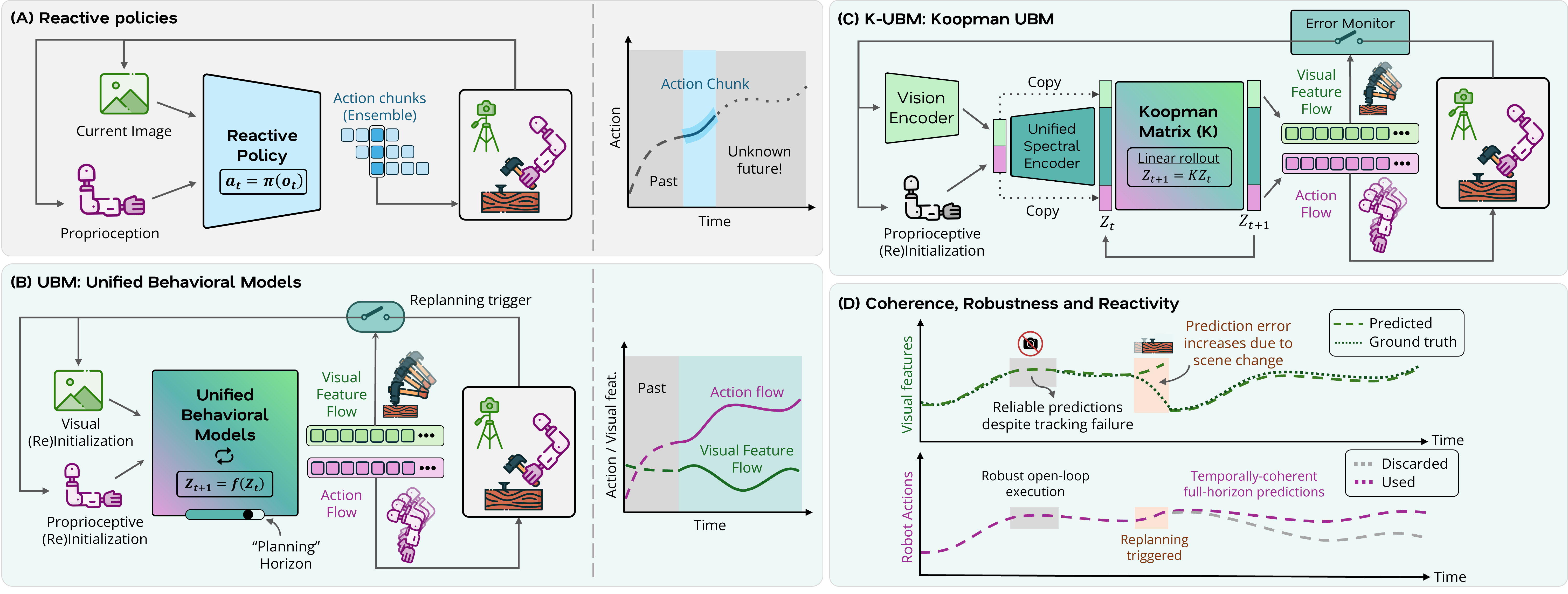
Unified Behavioral Models. Most policies model a skill as a reactive mapping from the current observation to a short action chunk. UBMs instead model a skill as a coupled dynamical system: the robot's proprioceptive state (action flow) and the environment's visual features (visual flow) co-evolve in a shared latent space. Given an initial condition, a UBM rolls this system forward over the entire skill horizon — producing temporally coherent behavior by construction rather than by averaging overlapping chunks.
From pixels to motion-centric features. We compress raw RGB into a compact, motion-centric representation and study two choices: (i) Object Flow — 256 points segmented with SAM 3 and tracked with CoTracker, then encoded by a convolutional autoencoder into a 128-d latent; and (ii) DynaMo — a ResNet-18 encoder trained with a self-supervised dynamics-consistency objective.
A latent where dynamics are linear. We form the unified behavioral state by concatenating the robot action with the visual feature, and lift it with a learned spectral encoder (an MLP) into a state-inclusive latent z. A single learned Koopman operator K then advances the latent linearly, zt+1 = K·zt. The encoder and operator are co-trained with a multi-step coherence loss; initializing K to the identity and updating it at a slower rate keeps training stable.
Pseudo planning with event-triggered replanning. Because the operator is linear, the full-horizon plan is generated by simply iterating K from the initial condition — no search or sampling, and the planning horizon is flexible. K-UBM also predicts the future visual flow, so it acts as its own runtime monitor: when the observed flow diverges from the prediction beyond a threshold, it re-initializes and replans, blending deliberate planning with reactive control.
Real-World Manipulation
Four tasks on a 7-DoF Franka arm with a 16-DoF LEAP hand (23-DoF state), 20 kinesthetic demos each. K-UBM reaches 85.0% success while cutting arm jerk ~6–9× and hand jerk ~3–4× versus Diffusion and ACT, at only 0.017 ms/step.
| Method | Success ↑ | Inference (ms/step) ↓ | Arm jerk ↓ | Hand jerk ↓ |
|---|---|---|---|---|
| Diffusion Policy | 72.5% | 26.4 | 44.7 | 14.2 |
| ACT | 92.5% | 0.058 | 28.4 | 16.6 |
| K-UBM (ours) | 85.0% | 0.017 | 5.0 | 4.1 |
Averaged over the four real-world tasks (RMS jerk in rad/s³). ACT has the highest success, but K-UBM stays competitive while producing far smoother motion — 6–9× lower arm jerk and 3–4× lower hand jerk — at the fastest inference.
Simulation Benchmarks

Seven simulated tasks: three DexArt (Bucket, Laptop, Toilet) and four Adroit (Door opening, Tool use, In-hand reorientation, Relocation).
We compare K-UBM against five baselines — Diffusion Policy, ACT, UVA, KODex, and KOROL — each evaluated with both Object Flow and DynaMo visual features. K-UBM attains the second-highest average success rate with the most consistent performance across tasks, and runs at ~0.4–0.5 ms/step — comparable to the fastest baselines and orders of magnitude faster than diffusion policy (~30 ms/step).
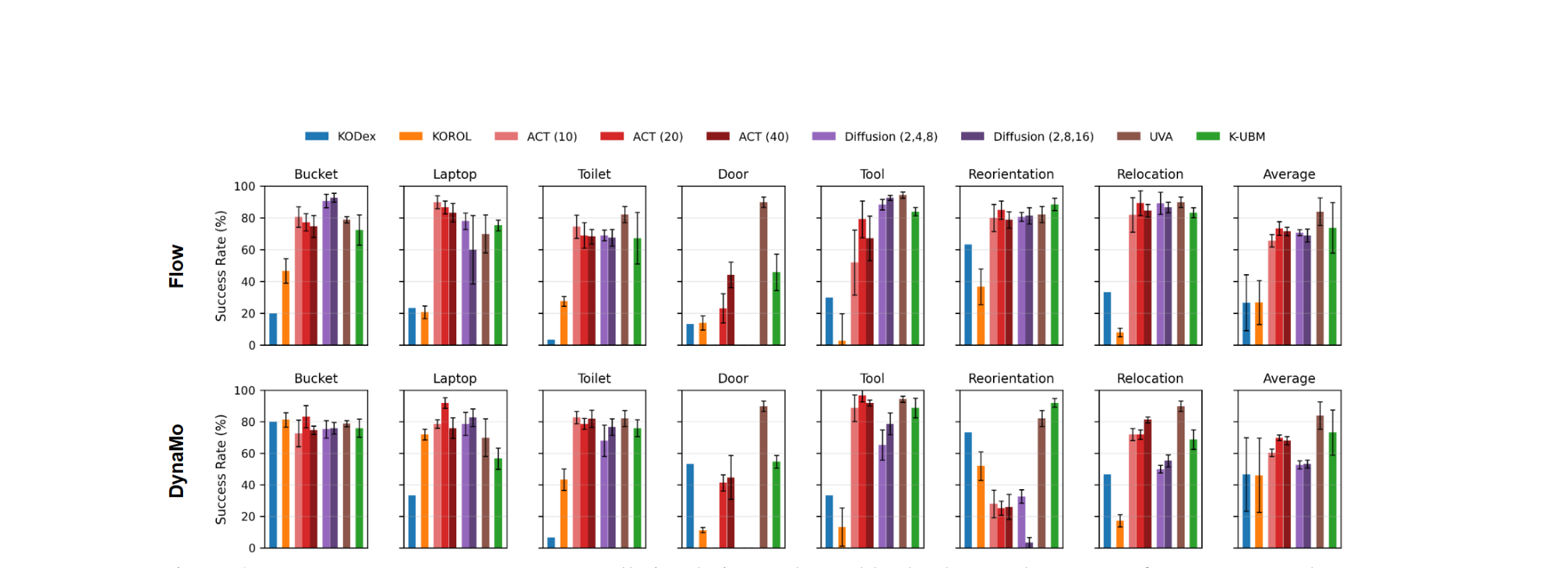
Success rates across the seven simulated tasks (mean ± std over 5 seeds) under two visual representations: Object Flow (top) and DynaMo (bottom). K-UBM is the green bar.
Robustness & Reactivity
Reactive policies falter when perception degrades — under strong occlusions or dropped frames they freeze or jitter. Because K-UBM carries an internal linear dynamics model, it can propagate the system’s “momentum” without sensory feedback, faithfully continuing the nominal plan to bridge perceptual gaps.
For unanticipated disturbances, K-UBM adds reactivity through event-triggered replanning. Since it explicitly predicts the future flow of visual features, the model monitors the gap between predicted and observed flow at runtime and re-initializes a fresh coherent plan only when that gap exceeds a threshold — navigating the spectrum between deliberate planning and reactive control without a hard-coded chunk size.
Real-world (flower arrangement) — raw camera view (left, real-time 1×) and the predicted-vs-observed visual flow (right). When the scene is disturbed mid-rollout, the gap between planned and observed (CoTracker) flow crosses the threshold and K-UBM triggers a fresh plan (replan) on the physical robot.
Baselines on the same task — Diffusion Policy (left) and ACT (right) run the identical flower-arrangement rollout with the same mid-rollout disturbance (real-time 1×). As purely reactive policies, they lack an explicit flow-prediction monitor, so they cannot detect the predicted-vs-observed divergence and re-initialize a coherent plan the way K-UBM does above.

Door — nominal trajectory (left) vs. the replan triggered (right) when the door is moved mid-rollout. The flow-centroid distance spikes, crossing the replan threshold.
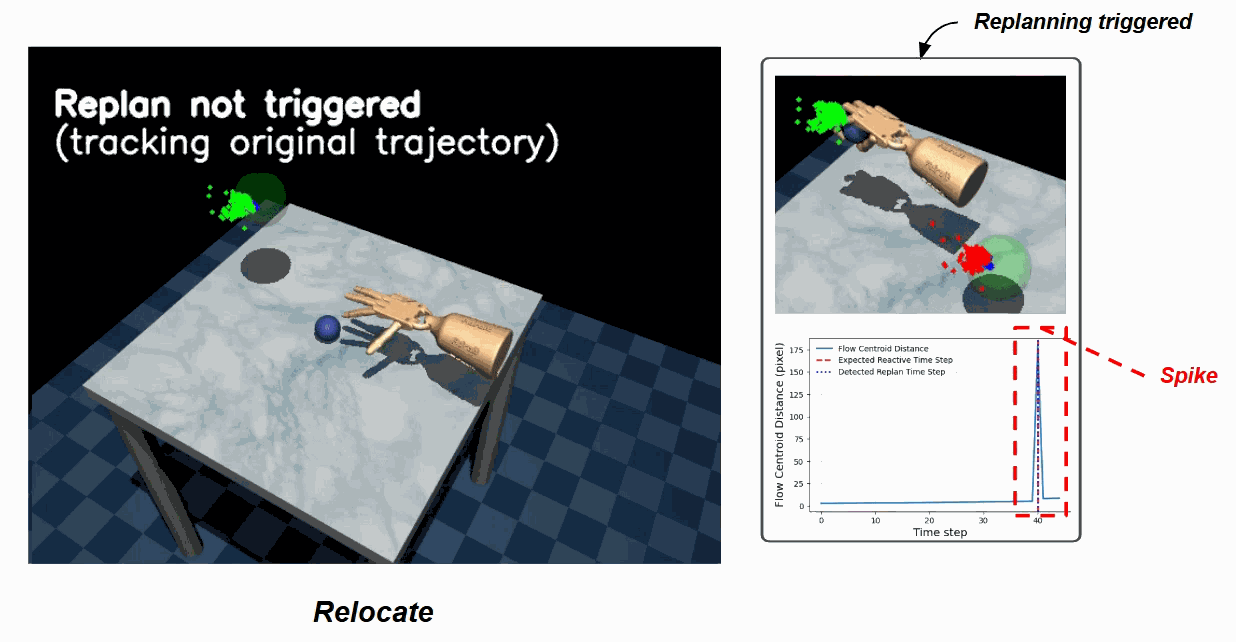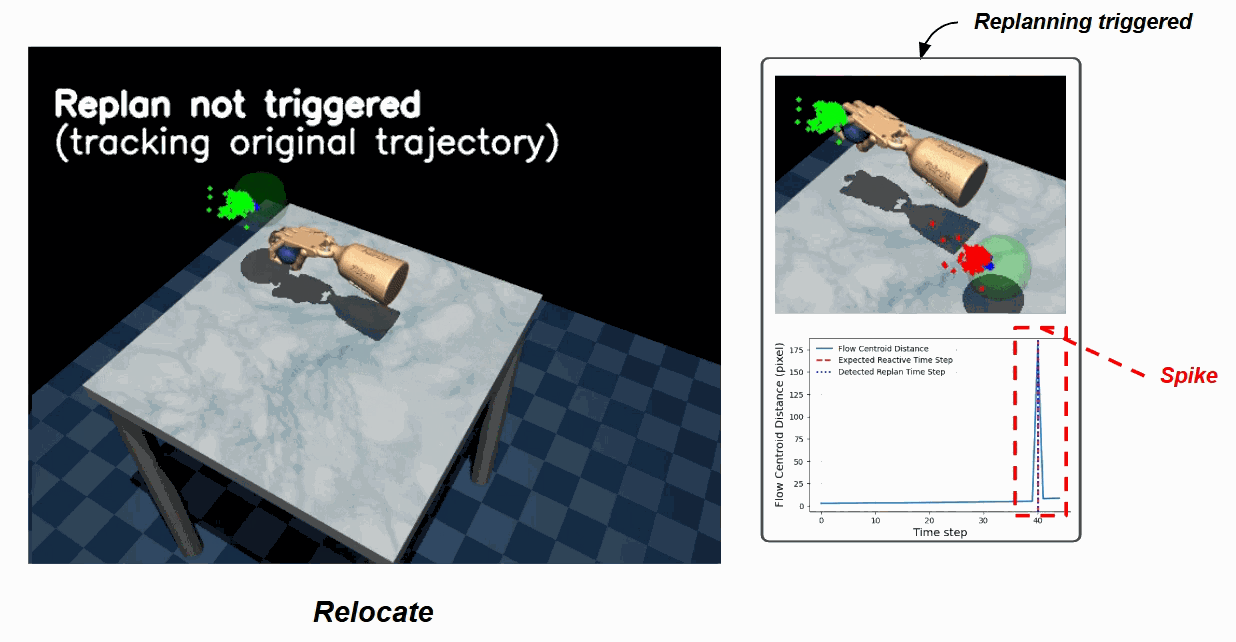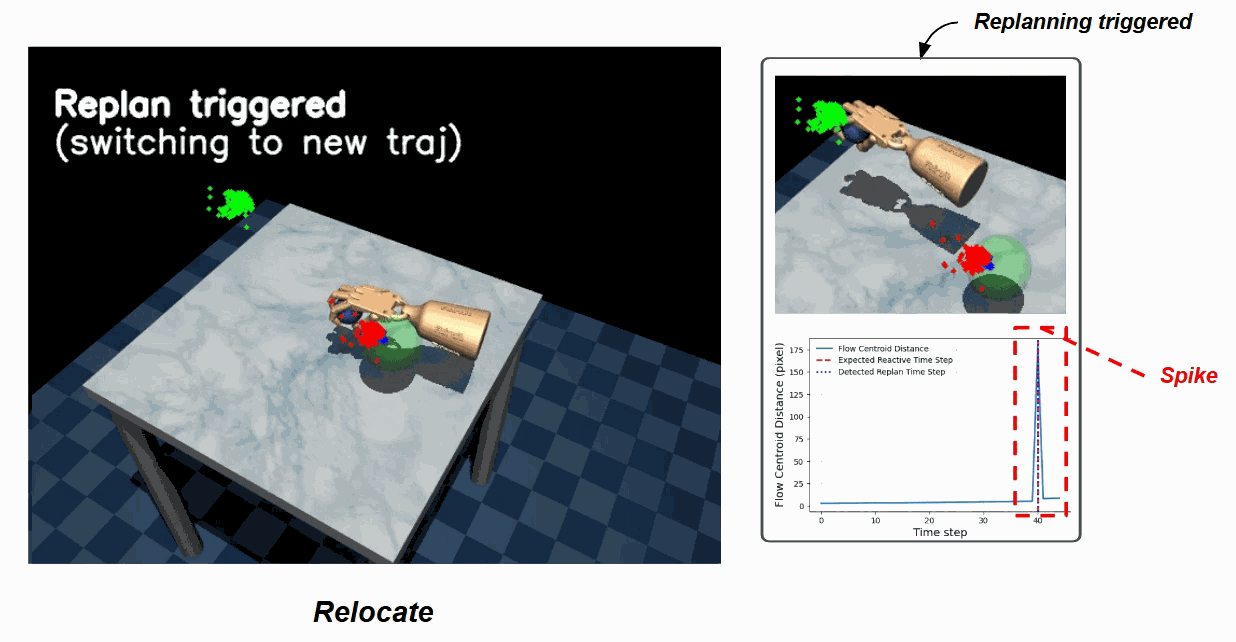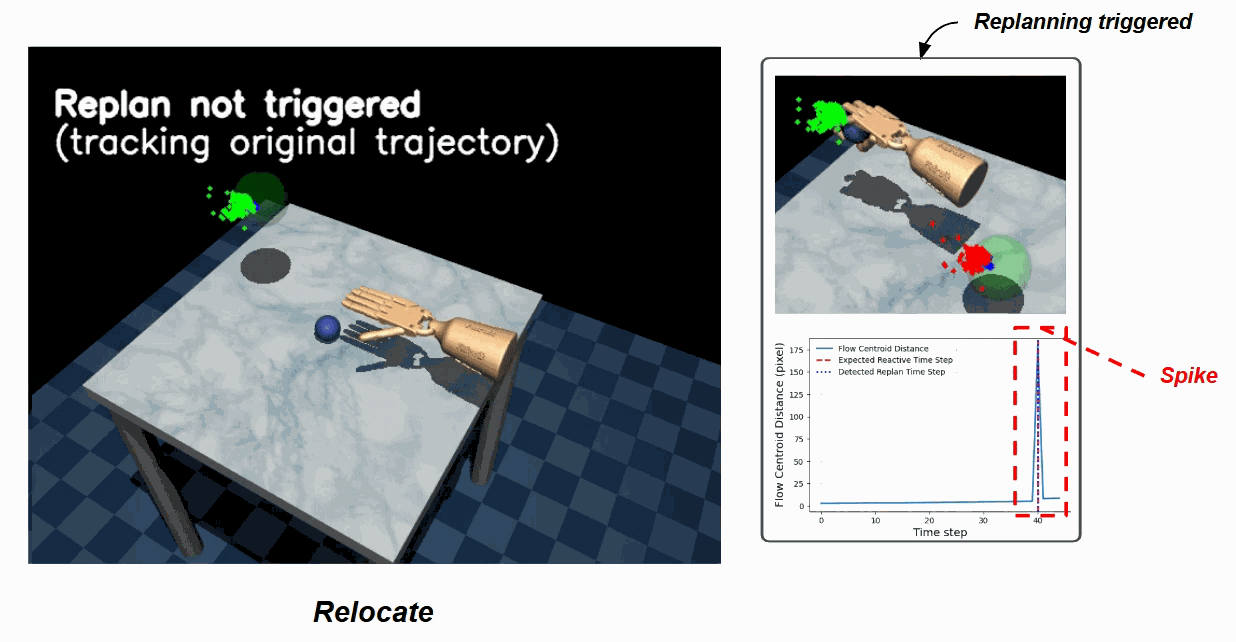
Relocate — the same trigger picks up an object pose change mid-rollout and seamlessly switches to a replanned trajectory.
BibTeX
@article{kubm,
title = {Going with the Flow: Koopman Behavioral Models as Pseudo Planners for Visuo-Motor Dexterity},
author = {Anonymous Author(s)},
journal = {Under review},
year = {2026}
}